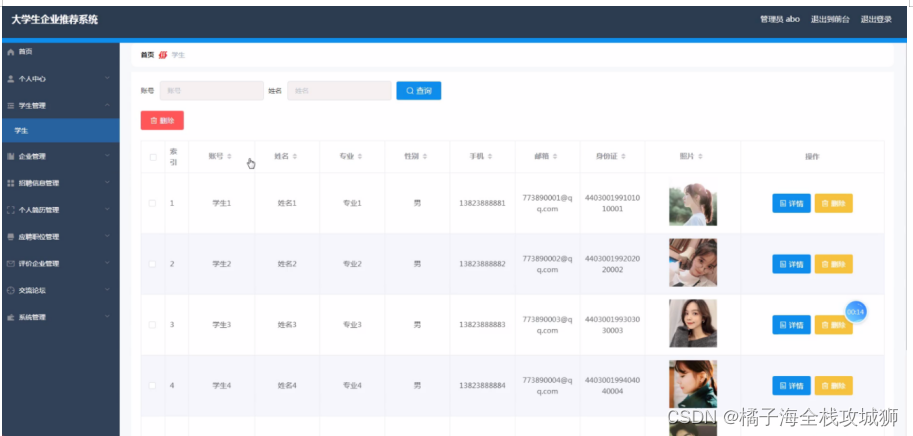
- 1 django- orm
- 2 peewee
- - - - - 同步orm框架- - - - -
- 3 sqlalchemy
- - - 中间态- - - -
- 4 Tortoise ORM
- 众多第三方库- - - 》都是同步的- - 》导致异步框架性能发挥不出来
- redis:aioredis - - 》redis- py
- mysql:aiomysql - - 》pymysql
- 2.0 .30 版本
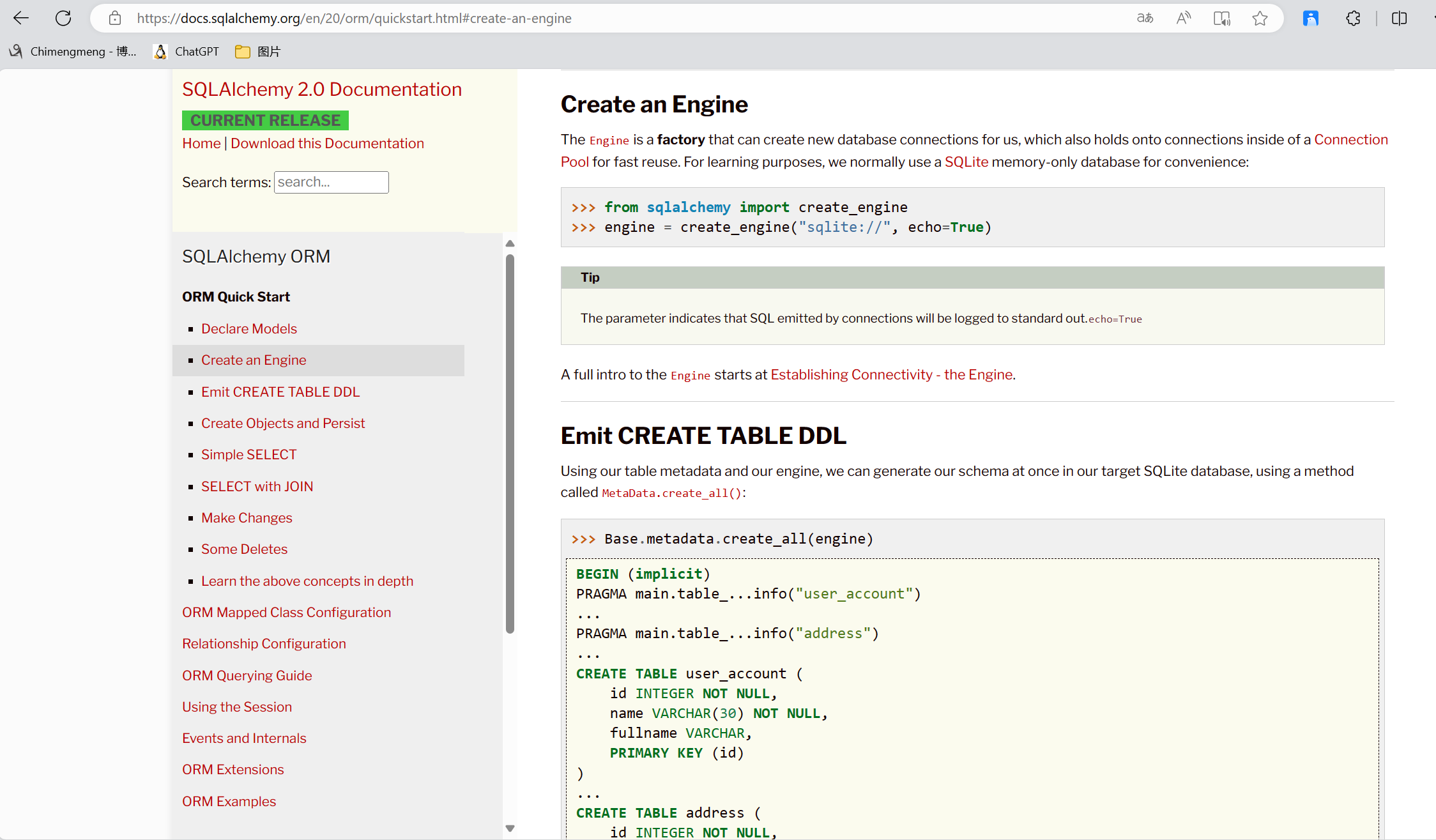
Engine,框架的引擎
Connection Pooling ,数据库连接池
Dialect,选择连接数据库的DB API种类
SQL Exprression Language,SQL表达式语言
engine = create_engine( "postgresql://scott:tiger@localhost/mydatabase" )
engine = create_engine( "postgresql+psycopg2://scott:tiger@localhost/mydatabase" )
engine = create_engine( "postgresql+pg8000://scott:tiger@localhost/mydatabase" )
engine = create_engine( "mysql://scott:tiger@localhost/foo" )
engine = create_engine( "mysql+mysqldb://scott:tiger@localhost/foo" )
engine = create_engine( "mysql+pymysql://scott:tiger@localhost/foo" )
engine = create_engine( "oracle://scott:tiger@127.0.0.1:1521/sidname" )
engine = create_engine( "oracle+cx_oracle://scott:tiger@tnsname" )
engine = create_engine( "mssql+pyodbc://scott:tiger@mydsn" )
engine = create_engine( "mssql+pymssql://scott:tiger@hostname:port/dbname" )
engine = create_engine( "sqlite:absolute/path/to/foo.db" )
engine = create_engine( "sqlite:///C:\\path\\to\\foo.db" )
engine = create_engine( r"sqlite:///C:\path\to\foo.db" )
import threading
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:1234@127.0.0.1:3306/cnblogs?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
def task ( ) :
conn = engine. raw_connection( )
cursor = conn. cursor( )
cursor. execute(
"select * from article"
)
result = cursor. fetchall( )
print ( result)
cursor. close( )
conn. close( )
for i in range ( 20 ) :
t = threading. Thread( target= task)
t. start( )
创建数据库引擎 :
使用 SQLAlchemy 的 create_engine 函数创建了一个 MySQL 数据库引擎。 连接字符串中包含了数据库的用户名、密码、地址、端口、数据库名以及字符集等信息。 设置了连接池的参数,如最大溢出连接数、连接池大小、等待超时时间以及连接的回收时间。 定义 task 函数 :
这个函数使用引擎的 raw_connection 方法来获取一个原始的数据库连接。 使用这个连接创建一个游标对象。 使用游标执行 SQL 查询,并从 info 表中获取所有记录。 打印查询结果。 关闭游标和连接。 创建并启动线程 :
使用 Python 的 threading 模块来创建多个线程。 每个线程都执行 task 函数,即并发地从数据库中查询数据。 这里创建了 20 个线程,但连接池的大小只设置为 5,这意味着在某些时刻,可能会有多个线程在等待从连接池中获取可用的连接。 import threading
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
def task ( ) :
conn = engine. raw_connection( )
cursor = conn. cursor( )
cursor. execute(
"select * from info"
)
result = cursor. fetchall( )
print ( result)
cursor. close( )
conn. close( )
for i in range ( 20 ) :
t = threading. Thread( target= task)
t. start( )
datetime.datetime.now不能加括号,加了括号,以后永远是当前时间 from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
import datetime
from sqlalchemy. orm import DeclarativeBase
class Base ( DeclarativeBase) :
pass
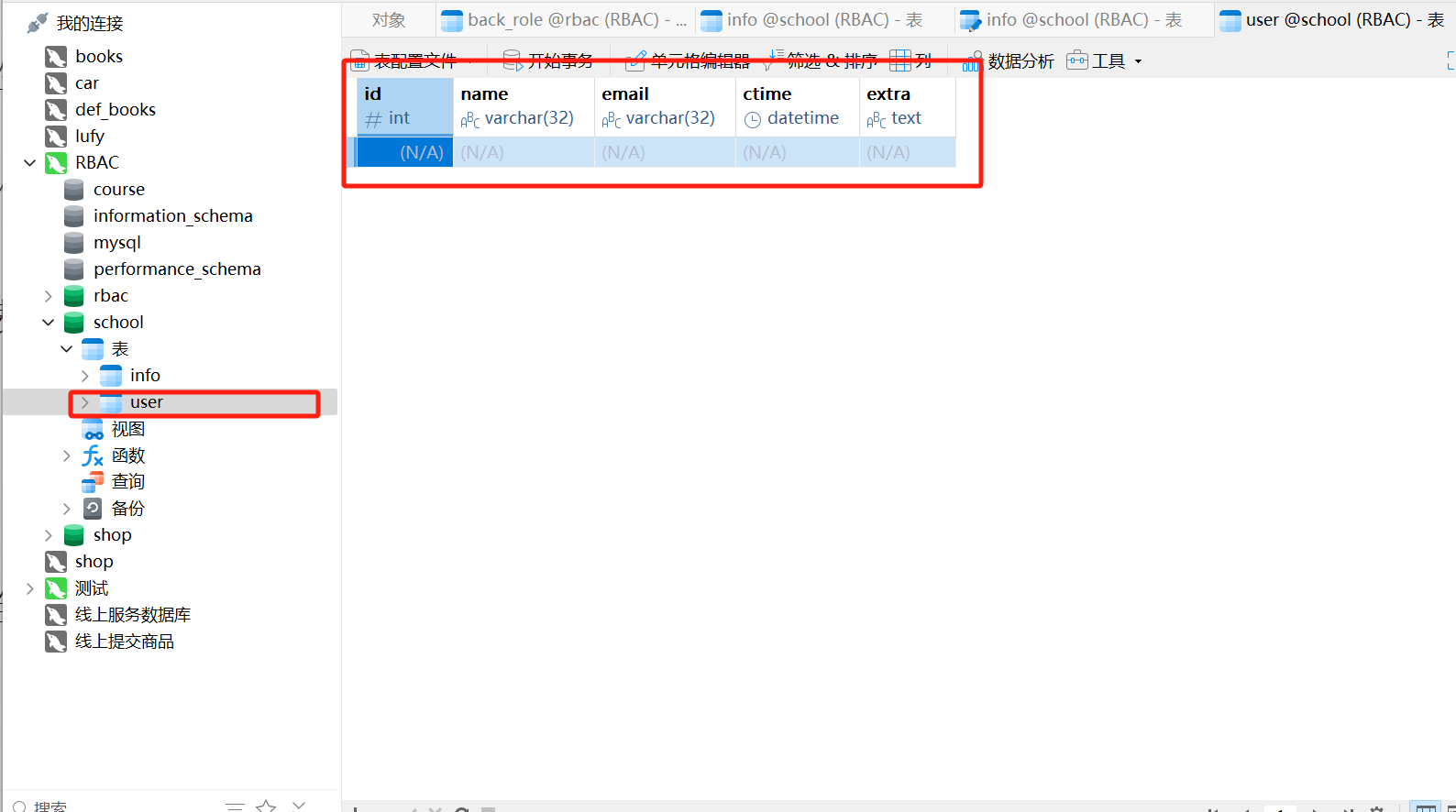
class User ( Base) :
__tablename__= 'user'
id = Column( Integer, primary_key= True , autoincrement= True )
name = Column( String( 32 ) , index= True , nullable= False )
email = Column( String( 32 ) , unique= True )
ctime = Column( DateTime, default= datetime. datetime. now)
extra = Column( Text, nullable= True )
if __name__ == '__main__' :
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:1234@127.0.0.1:3306/sqlalchemy001?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
Base. metadata. drop_all( engine)
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
import datetime
from sqlalchemy. orm import DeclarativeBase
class Base ( DeclarativeBase) :
pass
class User ( Base) :
__tablename__ = 'user'
id = Column( Integer, primary_key= True , autoincrement= True )
name = Column( String( 32 ) , index= True , nullable= False )
email = Column( String( 32 ) , unique= True )
ctime = Column( DateTime, default= datetime. datetime. now)
extra = Column( Text, nullable= True )
if __name__ == '__main__' :
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
Base. metadata. create_all( engine)
from models import User
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:1234@127.0.0.1:3306/sqlalchemy001?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
from sqlalchemy. orm import Session
session= Session( engine)
user1= User( name= 'lqz11' , email= '333@qq.com' )
user2= User( name= 'lqz12' , email= '335@qq.com' )
session. add_all( [ user1, user2] )
session. commit( )
session. close( )
from models import User
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
from sqlalchemy. orm import Session
session = Session( engine)
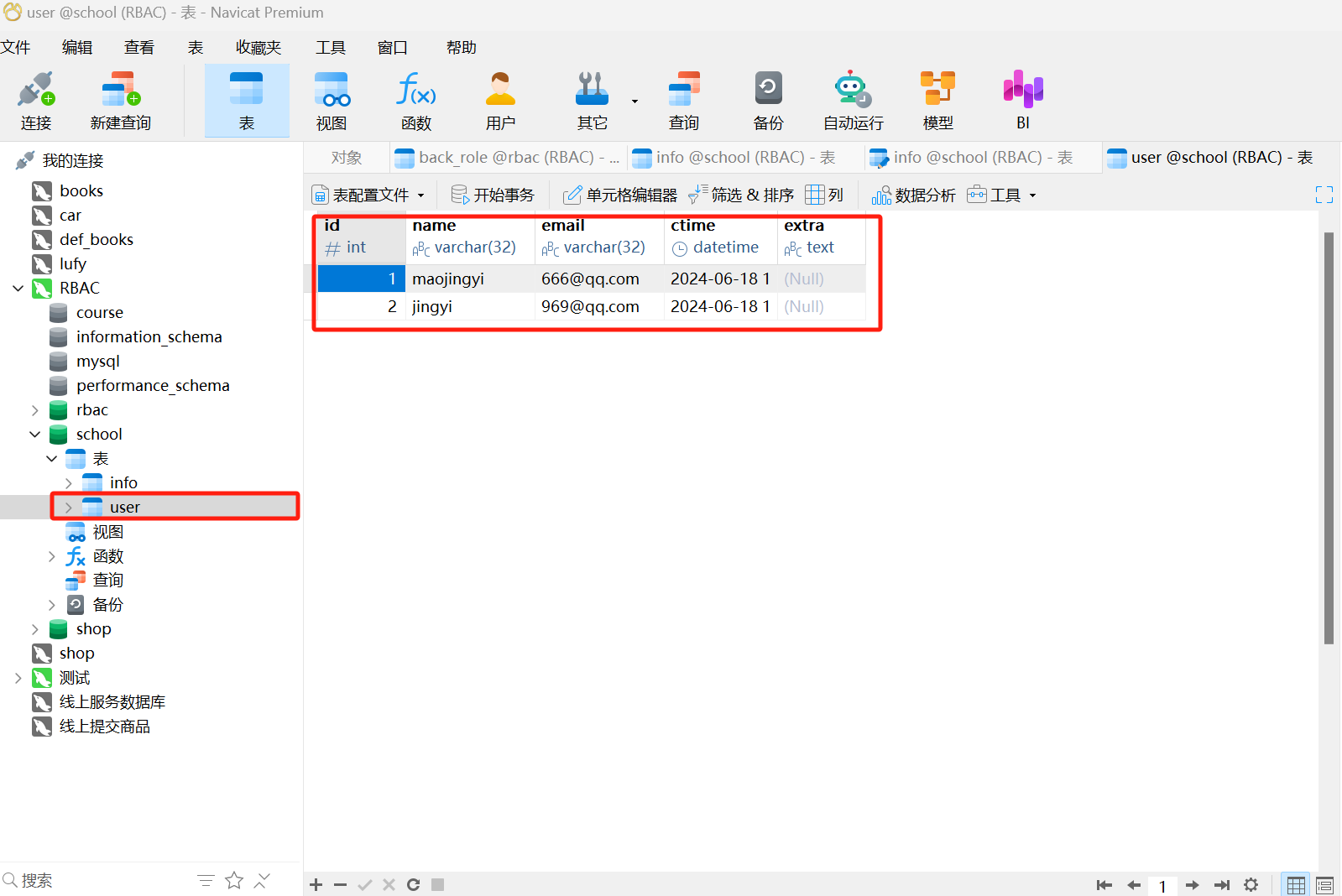
res1 = User( name= 'maojingyi' , email= '666@qq.com' )
res2 = User( name= 'jingyi' , email= '969@qq.com' )
session. add_all( [ res1, res2] )
session. commit( )
session. close( )
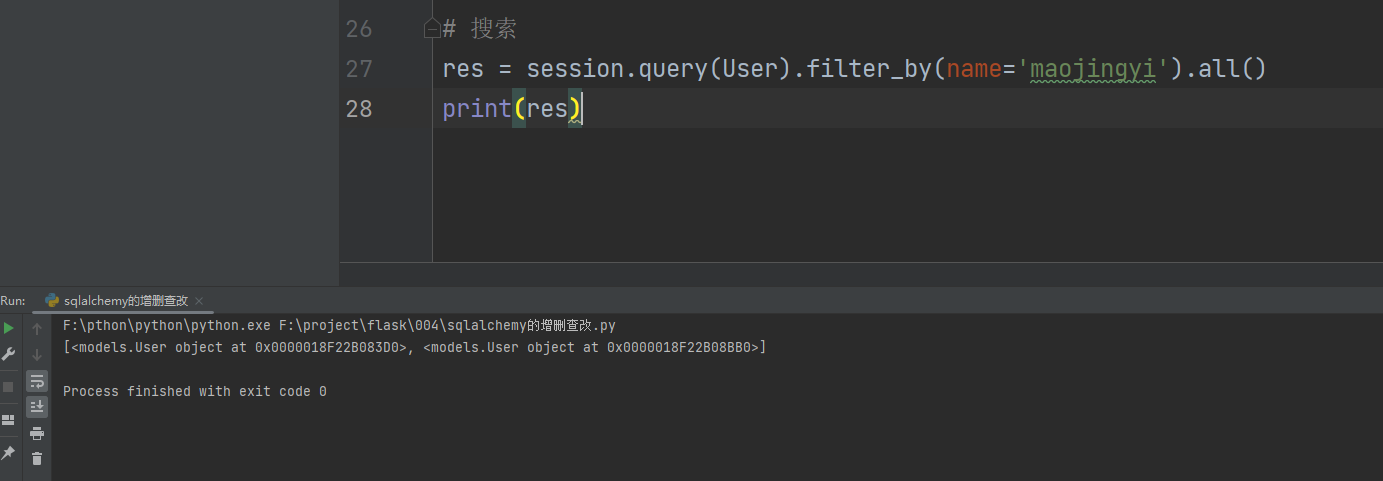
res = session. query( User) . filter_by( name= 'maojingyi' ) . all ( )
print ( res)
我们可以定制返回的形式 这个是在models.py的User表中写入 def __repr__ ( self) :
return f"<User(name= { self. name} , email= { self. email} )>"
res= session. query( User) . filter_by( name= 'maojingyi' ) . delete( )
print ( res)
session. commit( )
result = session. query( User) . filter ( User. id == 1 , User. email == '666@qq.com' ) . delete( )
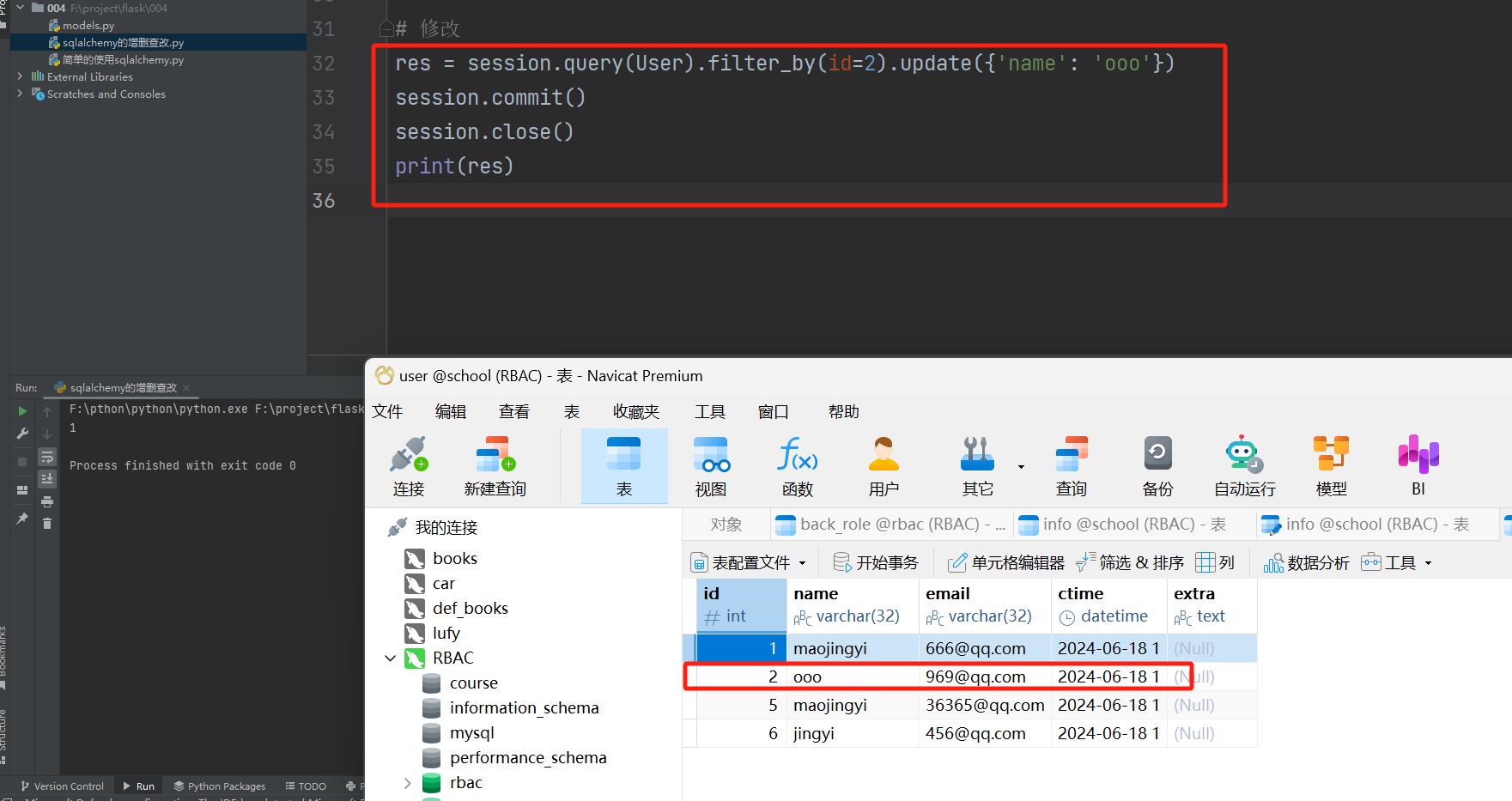
res = session. query( User) . filter_by( id = 2 ) . update( { 'name' : 'ooo' } )
session. commit( )
session. close( )
user= session. query( User) . filter_by( id = 2 ) . first( )
print ( user. name)